
TL;DR: Model collapse is a phenomenon where AI models trained on recursively generated data gradually lose their ability to produce accurate and diverse outputs [1] [2]. This occurs due to over-representation of common patterns and forgetting less-common elements. This results in a progressive loss of information and a decrease in the model’s ability to generate high-quality outputs. The phenomenon has been observed in various generative models, including large language models (LLMs) like GPT-3 and GPT-4, as well as in variational autoencoders (VAEs) and other generative models [1] [3]. To prevent model collapse, researchers suggest strategies like mixing real and synthetic data, using adaptive regularization, and accumulating data over time [4] [5]. While this remains a significant challenge, ongoing research aims to mitigate its effects [6].
Disclaimer: This post has been created with the help of generative AI. Including DALL-E, Gemini, OpenAI and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us
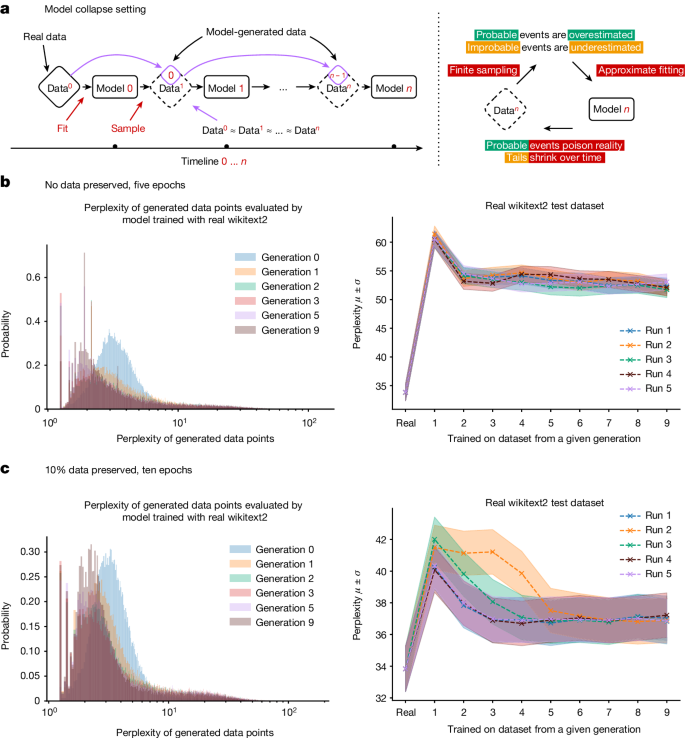
Model collapse refers to the phenomenon where AI models, when trained on data generated by other AI models (including their own previous outputs), begin to lose the diversity and depth of the original data distribution [1]. Over time, these models increasingly produce outputs that are repetitive, less accurate, and less reflective of the true distribution of human-generated data [2]. This process can ultimately lead to a scenario where the model’s outputs become degenerate, losing the ability to generate useful and meaningful content.
The concern of model collapse is particularly relevant as AI-generated content becomes more prevalent online. With more AI-generated data being used to train new models, the risk of recursively generated data leading to model collapse increases.
Causes of Model Collapse
The underlying causes of model collapse are multifaceted, involving several types of errors that accumulate over successive generations of training:
- Statistical Approximation Error: This error occurs due to the finite number of samples used in training. As models are trained on recursively generated data, rare events in the original data distribution may not be sampled frequently enough, leading to their gradual disappearance [1].
- Functional Expressivity Error: This error is related to the limitations in the model’s ability to approximate the true data distribution. As neural networks are not perfect approximators, they may introduce errors that compound over successive generations, leading to a divergence from the original distribution [1].
- Functional Approximation Error: This error arises from limitations in the learning procedures themselves, such as the choice of optimization algorithms or loss functions. These limitations can cause the model to overfit certain aspects of the data while ignoring others, leading to a progressively narrower understanding of the data [1].
Each of these errors contributes to the overall degradation of the model’s performance, ultimately leading to model collapse.
The Impact of Model Collapse on Different Generative Models
Model collapse is a universal issue that affects various types of generative models. Here’s how it manifests in some of the most common models:
- Generative Adversarial Networks (GANs): In GANs, model collapse can result in the generator producing a limited variety of outputs, often converging on a few specific examples, leading to a loss of diversity in the generated content.
- Variational Autoencoders (VAEs): In VAEs, model collapse may lead to the generated samples becoming less representative of the original data distribution, particularly in the tails, where the diversity of the content is crucial.
- Large Language Models (LLMs): LLMs like GPT-3 and GPT-4 are especially vulnerable to model collapse when trained on recursively generated data. As these models are fine-tuned on outputs generated by previous versions, they risk losing the richness and variety inherent in human language, resulting in repetitive and less coherent text generation.
Theoretical Insights: Why Model Collapse Happens
To understand why model collapse happens, it’s essential to delve into the theoretical foundations. One useful framework is the concept of Markov chains, which can model the progression of data through successive generations of training. In this model, each generation of data is dependent on the previous one. If certain rare events in the data are not sampled adequately, they will eventually disappear, leading to a narrowing of the model’s output.
Another theoretical approach involves analyzing the behavior of Gaussian models. It has been shown that when models are trained recursively on their own outputs, they tend to collapse to a distribution with zero variance over time. This means that the model’s outputs become increasingly repetitive and less diverse, losing the ability to generalize from the original data.
Identifying Early Signs of Model Collapse
Model collapse can go unnoticed as initial performance appears to improve while the model subtly loses accuracy on minority data. This issue arises from model-induced distribution shifts (MIDS) that embed biases into data, leading to fairness feedback loops and exacerbating inequalities over time [7].
Hidden Performance Decline: Models may show apparent gains in overall metrics while losing accuracy, especially on minority data.
Fairness Feedback Loops: MIDS can lead to fairness feedback loops, exacerbating biases in the model, even in datasets that initially appear unbiased. This problem can particularly harm the representation of minoritized groups, reinforcing existing disparities.
Algorithmic Reparation as a Solution: The concept of algorithmic reparation (AR) is introduced as a proactive approach to address these fairness issues. AR involves curating representative training data to correct biases and improve the model’s fairness over time. This section highlights the importance of recognizing and mitigating these unfairness feedback loops in machine learning systems.
Practical Examples: Model Collapse in Action
The effects of model collapse can be seen in practical scenarios, particularly in the case of large language models. For example, a study involving the fine-tuning of a language model on data generated by a previous version of the same model revealed a gradual decline in the model’s performance. Initially, the model performed well, but as it was trained on recursively generated data over multiple generations, the quality of its outputs deteriorated. The generated text became more repetitive, less accurate, and increasingly disconnected from the original training data.
This degradation was quantified using a metric known as perplexity, which measures how well a model predicts the next word in a sequence. As model collapse set in, the perplexity increased, indicating a decline in the model’s ability to generate coherent and contextually appropriate text.
The Broader Implications of Model Collapse
The implications of model collapse extend beyond individual models to the broader AI ecosystem. As more AI-generated content populates the internet, the risk of recursively generated data becoming a significant portion of training datasets increases. This could lead to a situation where AI models trained on this data produce outputs that are increasingly disconnected from the real world, reducing their utility and reliability.
Moreover, model collapse raises important questions about data provenance. As it becomes harder to distinguish between human-generated and AI-generated content, ensuring that future AI models are trained on high-quality, diverse data becomes more challenging. This underscores the need for robust mechanisms to track the provenance of training data and to filter out low-quality or AI-generated content.
Mitigating the Risks of Model Collapse
To mitigate the risks associated with model collapse, several strategies can be employed:
- Human-in-the-Loop Training: Involving humans in the training process can help ensure that models are exposed to a diverse range of data and do not become overly reliant on AI-generated content. This can include using human evaluators to filter and curate the training data.
- Data Provenance and Filtering: Developing methods to track the origin of training data can help distinguish between human-generated and AI-generated content. This may involve using metadata or other markers to identify the source of the data.
- Robust Evaluation Metrics: Implementing more comprehensive evaluation metrics that go beyond simple accuracy measures can help detect early signs of model collapse. For example, metrics that assess the diversity and richness of the model’s outputs can provide valuable insights into its performance.
- Continual Learning with Real-World Data: To prevent models from collapsing, it is crucial to continue training them on real-world data that accurately reflects the full distribution of human language and experience. This may involve supplementing web-scraped data with carefully curated datasets that are less likely to contain AI-generated content.
The Future of Generative AI and the Challenges of Model Collapse
As AI technology continues to advance, the challenge of model collapse will become increasingly important. Ensuring that AI models remain robust and capable of generating high-quality content requires a careful balance between innovation and the preservation of data integrity. By understanding the causes and implications of model collapse, and by implementing strategies to mitigate its risks, we can continue to harness the power of generative AI while safeguarding its future potential.
In conclusion, model collapse is a significant issue that must be addressed to ensure the continued success and reliability of generative AI. As the use of AI-generated content grows, so too does the importance of maintaining the integrity of the data used to train these models. By taking proactive steps to mitigate the risks of recursively generated data, we can ensure the long-term sustainability and reliability of AI systems.
References
[1] Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., & Gal, Y. (2024). AI models collapse when trained on recursively generated data. Nature, 631(8022), 755-759. https://doi.org/10.1038/s41586-024-07566-y
[2] Shumailov, I., Shumaylov, Z., Zhao, Y., Gal, Y., Papernot, N., & Anderson, R. (2023). The Curse of Recursion: Training on Generated Data Makes Models Forget. ArXiv. /abs/2305.17493
[3] Wenger, E. (2024). AI produces gibberish when trained on too much AI-generated data. Nature, 631(8022), 742-743. https://doi.org/10.1038/d41586-024-02355-z
[4] Gerstgrasser, M., Schaeffer, R., Dey, A., Rafailov, R., Sleight, H., Hughes, J., Korbak, T., Agrawal, R., Pai, D., Gromov, A., Roberts, D. A., Yang, D., Donoho, D. L., & Koyejo, S. (2024). Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data. ArXiv. /abs/2404.01413
[5] Seddik, M. E., Chen, S., Hayou, S., Youssef, P., & Debbah, M. (2024). How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse. ArXiv. /abs/2404.05090
[6] Coldewey, D. ‘Model collapse’: Scientists warn against letting AI eat its own tail. TechCrunch. https://techcrunch.com/2024/07/24/model-collapse-scientists-warn-against-letting-ai-eat-its-own-tail/
[7] Wyllie, S., Shumailov, I., & Papernot, N. (2024). Fairness Feedback Loops: Training on Synthetic Data Amplifies Bias. ArXiv. /abs/2403.07857
Follow me on Twitter and LinkedIn for new content on generative AI. Check out Generative AI Lab for some experiments. Last but not least, join Learn AI Together by Towards AI and let’s explore the world of AI together.


Hands-On Large Language Models: Language Understanding and Generation
40% Off
Now retrieving an image set.
ChatGPT AND GENERATIVE AI SIMPLIFIED: NAVIGATE ARTIFICIAL INTELLIGENCE WITH CONFIDENCE, CRAFT EFFECTIVE PROMPTS, BOOST WRITING CREATIVITY AND ENHANCE LEARNING & SKILL DEVELOPMENT
$4.99 (as of November 12, 2025 13:41 GMT -04:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Now retrieving an image set.

