TL;DR: For aspiring data scientists:
1. Learn programming and statistics
2. Gain practical experience through internships or projects
3. Keep learning and stay updated with new technologies
4. Prepare for a competitive job market
5. Don’t underestimate the importance of communication skills.
As a data science student, be ready for a challenging but rewarding journey.
Disclaimer: This post has been created automatically using generative AI. Including DALL-E, Gemini, OpenAI and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us
Introduction
Becoming a data scientist is a highly sought-after career path in today’s digital age. With the rise of big data and the increasing demand for data-driven decision-making, it’s no surprise that many individuals are interested in pursuing this field. However, before diving into the world of data science, it’s important to have a clear understanding of what it entails and what to expect. As someone who has gone through the journey of becoming a data scientist, I have some honest advice to share for those who are considering this career path.
Understand the Basics of Data Science
Before jumping into data science, it’s crucial to have a solid understanding of the basics. This includes knowledge of programming languages such as Python and R, as well as statistical concepts like regression and hypothesis testing. It’s also important to have a good grasp of machine learning algorithms and how they work. Without a strong foundation in these areas, it can be challenging to excel in the field of data science.
Build a Strong Foundation in Mathematics and Statistics
Data science is a highly analytical field, and having a strong foundation in mathematics and statistics is essential. It’s important to have a good understanding of concepts like linear algebra, calculus, and probability. These skills will be crucial in data analysis and building predictive models. If you have a weak background in these areas, it’s worth investing time in brushing up on these skills before diving into data science.
Gain Hands-On Experience
While having a theoretical understanding of data science is important, it’s equally crucial to have practical experience. This can be achieved through internships, online courses, or personal projects. Having hands-on experience will not only help you understand the concepts better but will also give you a chance to showcase your skills to potential employers. It’s also a great way to build a portfolio and stand out in a competitive job market.
Stay Updated with the Latest Tools and Technologies
The field of data science is constantly evolving, and it’s essential to stay updated with the latest tools and technologies. This includes programming languages, libraries, and frameworks used in data science. It’s also important to keep up with industry trends and advancements in machine learning and artificial intelligence. This will not only make you more marketable but will also help you stay ahead in your career.
Don’t be Afraid to Ask for Help
Data science can be a challenging field, and it’s okay to ask for help. Whether it’s from a mentor, a colleague, or an online community, don’t be afraid to reach out for assistance when needed.
In conclusion, becoming a data scientist is a challenging and rewarding journey. It requires a lot of hard work, dedication, and continuous learning. My honest advice for someone who wants to pursue this path is to be prepared for a steep learning curve, but also to not be discouraged by it. It is important to have a strong foundation in mathematics, programming, and statistics, but also to have a curious and analytical mindset. Additionally, I wish someone would have told me before studying data science that it is not just about technical skills, but also about effective communication and problem-solving. So, my final advice would be to not only focus on building technical skills, but also on developing soft skills that are equally important in this field. With determination and a growth mindset, anyone can become a successful data scientist.
Join us on this incredible generative AI journey and be a part of the revolution. Stay tuned for updates and insights on generative AI by following us on X or LinkedIn.
TL;DR: Prepare for data analyst interviews by practicing with AI. Use online resources and mock interviews to improve technical skills and boost confidence. Focus on problem-solving and communication skills to ace the real interview.
Disclaimer: This post has been created automatically using generative AI. Including DALL-E, Gemini, OpenAI and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us
Introduction
As the field of data analysis continues to grow and evolve, the demand for skilled data analysts is on the rise. This has led to a highly competitive job market, especially when it comes to securing a data analyst position at top companies. One way to stand out from the competition is to ace the data analyst interview. However, preparing for these interviews can be a daunting task. Luckily, with the advancements in technology, there are now AI tools that can help you practice for data analyst interviews. In this blog post, we will discuss how to use AI to practice data analyst interviews.
Understanding the Types of Data Analyst Interviews
Before we dive into how AI can help with data analyst interviews, it’s essential to understand the different types of interviews you may encounter. The most common types of data analyst interviews are technical interviews, case study interviews, and behavioral interviews. Technical interviews test your technical skills and knowledge, while case study interviews assess your problem-solving abilities. Behavioral interviews focus on your past experiences and how you handle different situations. Each type of interview requires a different approach, and AI tools can help you prepare for all of them.
Utilizing AI for Technical Interviews
Technical interviews are often the most challenging part of the data analyst interview process. They require a strong understanding of data analysis concepts, coding languages, and tools. AI tools can help you practice technical questions and assess your performance. These tools use machine learning algorithms to generate questions based on your skill level and provide immediate feedback on your answers. This allows you to identify your strengths and weaknesses and focus on improving where needed.
Preparing for Case Study Interviews with AI
Case study interviews are designed to evaluate your problem-solving skills. They typically involve analyzing a real-world data set and presenting your findings and recommendations. AI tools can help you practice for these interviews by providing you with case studies and simulating a real interview experience. These tools can also provide feedback on your presentation skills, helping you improve your delivery and communication.
Improving Behavioral Interview Skills with AI
Behavioral interviews are all about showcasing your past experiences and how you handle different situations. AI tools can assist you in preparing for these interviews by providing a list of commonly asked behavioral questions and allowing you to practice your responses. These tools can also analyze your answers and give you feedback on your communication skills and the relevance of your responses.
Other Benefits of Using AI for Data Analyst Interviews
In conclusion, practicing data analyst interviews with AI can greatly improve one’s skills and confidence in this field. By using AI technology, individuals can simulate real-life interview scenarios and receive personalized feedback to enhance their performance. It is a cost-effective and efficient way to prepare for data analyst interviews and can ultimately lead to success in securing a job in this competitive industry.
Join us on this incredible generative AI journey and be a part of the revolution. Stay tuned for updates and insights on generative AI by following us on X or LinkedIn.
TL;DR: 4 visualization libraries that work with Pandas dataframe and use its plotting backend for easy plotting. They are Matplotlib, Seaborn, Plotly, and Altair. Each has its unique features and can produce high-quality visuals with minimal coding. Try them out to enhance your data analysis!
Disclaimer: This post has been created automatically using generative AI. Including DALL-E, Gemini, OpenAI and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us
Four Visualisation Libraries That Seamlessly Integrate With Pandas Dataframe
Data visualization is an essential aspect of data analysis. It allows us to explore and understand our data in a visual format, making it easier to identify patterns, trends, and insights. When it comes to data analysis in Python, Pandas is a popular library for data manipulation and analysis. However, Pandas also has a built-in plotting backend that allows for basic visualizations. For more advanced and customizable visualizations, we can turn to other libraries that seamlessly integrate with Pandas dataframes. In this blog post, we will explore four such libraries that make use of Pandas plotting backend for the easiest plotting.
Matplotlib
Matplotlib is a popular visualization library in the Python community. It offers a wide range of customizable plots, including line plots, scatter plots, histograms, bar charts, and more. One of the key advantages of Matplotlib is its seamless integration with Pandas dataframes. We can easily plot data from a Pandas dataframe using Matplotlib’s pyplot interface, which allows for customization of various plot elements such as axes, labels, and legends. With Matplotlib, we can also create subplots and combine multiple plots in a single figure, making it a powerful tool for data visualization.
Seaborn
Seaborn is another popular visualization library that builds on top of Matplotlib. It offers a higher-level interface for creating more sophisticated and visually appealing plots. Seaborn is particularly useful for statistical data visualization, with built-in functions for plotting regression models, categorical data, and more. Like Matplotlib, Seaborn also seamlessly integrates with Pandas dataframes, making it easy to create visualizations from our data. Additionally, Seaborn offers a wide range of customizable color palettes, making our plots more aesthetically pleasing.
Plotly
Plotly is a powerful visualization library that offers interactive and dynamic plots. It allows us to create interactive visualizations such as scatter plots, line plots, bar charts, and more. Plotly’s integration with Pandas dataframes is straightforward, and we can easily convert our dataframe into a Plotly graph object. With Plotly, we can create interactive plots with hover effects, zooming, and panning, making it easier to explore and analyze our data. We can also share our interactive plots with others through Plotly’s online platform.
Altair
Altair is a relatively new visualization library that has gained popularity for its declarative approach to creating visualizations. It uses a simple and intuitive
In conclusion, using visualisation libraries that seamlessly integrate with Pandas Dataframe and make use of Pandas plotting backend can greatly simplify the process of creating plots and charts. This integration allows for easy access to powerful visualisation tools while still utilizing the familiar and efficient Pandas framework. By taking advantage of these libraries, users can quickly and easily create high-quality visualisations from their data, making data analysis and communication more efficient and effective.
Join us on this incredible generative AI journey and be a part of the revolution. Stay tuned for updates and insights on generative AI by following us on X or LinkedIn.
TL;DR: This blog explores the challenges of causal inference when strategic behavior is involved, highlighting how individuals’ actions can influence data and skew results. It discusses methods like incentivizing compliance, using strategic instrumental variables, and algorithmic reparation to address these challenges. The post emphasizes the importance of understanding and mitigating the impact of strategic behavior in various fields, from healthcare to online platforms, to ensure accurate and fair causal inference outcomes.
Disclaimer: This post has been created automatically using generative AI, including DALL-E, Gemini, OpenAI, and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us.
Causal inference is a critical field that seeks to understand the relationship between cause and effect, using statistical methods to separate mere correlations from true causations. In various fields, such as healthcare, economics, and online platforms, learning these causal relationships from data is vital. However, a unique challenge arises when individuals involved in the causal inference process are strategic, meaning they can influence or alter the data based on their preferences, potentially skewing the outcomes. This blog post delves into the intricate intersection of causal inference and game theory, with a particular focus on the complications introduced by strategic agents.
Causal Inference and Strategic Behavior
The conventional approach to causal inference assumes that individuals are passive subjects whose data merely reflects the world as it is. However, in many real-world scenarios, individuals can be strategic. They might have incentives to alter their behavior or the information they provide to receive a more favorable outcome, complicating the causal inference process.
For instance, consider a clinical trial where participants might not adhere to the treatment assigned to them because they believe another treatment might be more beneficial. This non-compliance can skew the results, making it difficult to draw accurate conclusions about the causal relationship between the treatment and the outcome. Similarly, in online advertising, users might deliberately interact with certain ads to receive more relevant or personalized content, thereby influencing the data collected for causal analysis.
Challenges in Causal Inference Under Strategic Behavior
Strategic behavior introduces several challenges in causal inference, which can significantly affect the reliability of the conclusions drawn. Here are some key issues:
1. Non-Compliance in Randomized Trials: When participants in a randomized control trial do not adhere to their assigned treatment, it becomes challenging to infer causal relationships. This issue is addressed by [Robins 1998], who explores methods to correct for non-compliance and ensure more accurate results.
2. Instrumental Variables and Strategic Responses: Instrumental variable (IV) methods are commonly used to estimate causal effects, especially when dealing with confounding variables. However, as discussed by [Harris et al. 2022], strategic behavior can complicate the use of IVs, as individuals might alter their observable characteristics to influence their treatment assignment.
3. Fairness Feedback Loops: As noted by [Wang et al. 2023], when strategic individuals affect the data used for causal inference, it can lead to fairness feedback loops. These loops can perpetuate biases, particularly in scenarios where individuals self-select into treatments or modify their behavior to receive more favorable outcomes.
Addressing Strategic Behavior in Causal Inference
Given the challenges introduced by strategic behavior, researchers have proposed several methods to mitigate its impact on causal inference:
1. Incentivizing Compliance: [Ngo et al. 2021] suggests using tools from information design to create incentives for participants to comply with the treatment assigned to them. By revealing information about the effectiveness of treatments, researchers can encourage individuals to follow through with the prescribed regimen, thereby improving the accuracy of causal inference.
2. Strategic Instrumental Variables: [Harris et al. 2022] proposes the use of strategic instrumental variables, which account for the strategic behavior of individuals. This approach allows researchers to recover causal relationships even in the presence of strategic responses, providing a more robust framework for causal analysis.
3. Algorithmic Reparation: The concept of algorithmic reparation, as introduced by [Wang et al. 2023], involves curating representative training data to correct biases introduced by strategic behavior. This approach aims to enhance the fairness of causal inference by addressing the underlying issues in the data.
Implications and Future Directions
The interplay between causal inference and strategic behavior has far-reaching implications across various domains. In healthcare, ensuring compliance in clinical trials is crucial for developing effective treatments. In online platforms, understanding user behavior and its impact on advertising and recommendation systems is essential for optimizing algorithms. As more data is generated and used for decision-making, addressing the challenges of strategic behavior in causal inference will become increasingly important.
Conclusion
Causal inference under incentives is a complex but crucial area of study that bridges the gap between statistical methods and game theory. As individuals and systems become more strategic, the need for robust methods to account for these behaviors grows. By understanding and addressing the challenges posed by strategic behavior, researchers can ensure more accurate and fair outcomes in causal inference.
In conclusion, the intersection of causal inference and game theory presents a rich area for future research, with significant implications for various fields. As we continue to develop new methods and approaches, it is essential to keep fairness and accuracy at the forefront, ensuring that the benefits of causal inference are realized without unintended consequences.
References
[1] Robins, J. M. (1998). Correction for non-compliance in equivalence trials. *Statistics in Medicine, 17*(3), 269-302.
[2] Harris, K., Ngo, D. D. T., Stapleton, L., Heidari, H., & Wu, S. (2022). Strategic instrumental variable regression: Recovering causal relationships from strategic responses. *International Conference on Machine Learning*, 8502–8522.
[3] Wang, S., Bates, S., Aronow, P., & Jordan, M. I. (2023). Operationalizing counterfactual metrics: Incentives, ranking, and information asymmetry. *arXiv preprint arXiv:2305.14595*.
Crafted using generative AI from insights found on ML@CMU.
Join us on this incredible generative AI journey and be a part of the revolution. Stay tuned for updates and insights on generative AI by following us on X or LinkedIn.
TL;DR: Vision Transformer (ViT) is a new deep learning model for image recognition that uses self-attention mechanisms to replace convolutional layers. It has achieved impressive results on various tasks, but still has limitations in handling large images and requires a large amount of data for training.
Disclaimer: This post has been created automatically using generative AI. Including DALL-E, Gemini, OpenAI and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us
Introduction to Vision Transformer (ViT)
Vision Transformer (ViT) is a recent breakthrough in the field of computer vision that has gained a lot of attention from researchers and practitioners alike. It is a new approach to image recognition that uses a transformer-based architecture, which was originally developed for natural language processing (NLP). In this blog post, we will provide a paper walkthrough of the original ViT paper, published by Google researchers in 2020. We will explain the key concepts and ideas behind ViT and highlight its potential applications in the real world.
Understanding the Transformer Architecture
Before diving into ViT, it is essential to understand the transformer architecture. It is a type of neural network that uses self-attention mechanisms to process sequential data. In simple terms, it allows the model to focus on different parts of the input sequence at each step, making it more efficient in capturing long-term dependencies. The transformer architecture has been highly successful in NLP tasks, and the ViT paper proposes its use in computer vision.
ViT Architecture and Training
The ViT architecture consists of two main components: the patch embedding layer and the transformer encoder. The patch embedding layer divides the input image into smaller patches and converts them into a sequence of vectors, which are then fed into the transformer encoder. The transformer encoder consists of multiple layers, each containing a self-attention mechanism and a feed-forward network. The model is trained on a large dataset of images using a combination of supervised and self-supervised learning techniques.
Key Results and Findings
The ViT paper presents impressive results on various image recognition tasks, including image classification, object detection, and semantic segmentation. The model outperforms traditional convolutional neural networks (CNNs) on several benchmark datasets, showing its potential for real-world applications. The authors also conduct ablation studies to analyze the impact of different components of the ViT architecture, providing insights into its working.
Limitations and Future Directions
Despite its success, ViT has some limitations that need to be addressed in future research. One of the main challenges is the high computational cost, as the transformer architecture requires a lot of memory and processing power. This makes it difficult to apply ViT to large-scale datasets and real-time applications. Researchers are currently exploring ways to optimize the architecture and make it more efficient.
Conclusion
In conclusion, the Paper Walkthrough on Vision Transformer (ViT) provides a clear and concise understanding of this new and promising approach to image recognition. By breaking down the key concepts and techniques used in ViT, this walkthrough serves as a helpful guide for anyone interested in the field of computer vision. With its simple and straightforward explanation, it is a valuable resource for both beginners and experts alike. Overall, the ViT paper offers a promising advancement in the world of image recognition and this walkthrough serves as a great starting point to dive deeper into the topic.
Join us on this incredible generative AI journey and be a part of the revolution. Stay tuned for updates and insights on generative AI by following us on X or LinkedIn.
TL;DR: I’ve been an avid World of Warcraft player since its release in 2004, even during times when I had to take a break to focus on personal projects. In this post, I decided to blend my love for the game with my appreciation for Peru’s hidden landscapes. Using image generation models like DALL-E and Midjourney, I’ll create visuals that merge the mystical realms of Warcraft with the breathtaking scenery of Peru. These creations will be inspired by various World of Warcraft lore books, bringing a unique fusion of fantasy and reality to life.
Disclaimer: This post has been created with the help of generative AI. Including DALL-E, Gemini, OpenAI, and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us.
I’ve always been a fan of World of Warcraft. Hands down, it’s my favorite game. I’ve been playing it off and on since Vanilla days in 2004. Back then, I couldn’t afford it, as I was still living in Peru, and $15.00 a month was a bit hefty then. So, my friends at the internet cafe were kind enough to either let me borrow their account or set me up on a private server to play.
Then, I moved to the US in 2008, and even though I couldn’t speak English, I got a couple of jobs at Subway and Sonic, and I could finally afford a Blizzard account. I remember eating Subway for lunch, a bag of Doritos, and a Pepsi for dinner while playing World of Warcraft—fun times. In 2009, I moved back to Peru to study (maybe I can talk about that another day). Peru is a beautiful country, and it has, in my opinion, a limitless number of beautiful places to visit. For instance, check out some images generated in Peru and their prompts.
In this blog post, I will blend these two worlds using image generation models. I’ll use DALL-E, Midjourney, and Photoshop to make the images pop a bit more. To make it fun, I’ll use some of the World of Warcraft lore and not-so-known places in Peru for the prompts. So, let’s see what we come up with.
Fusion of Myth and Reality: Machu Picchu Meets the Mystical Warcraft Chronicle
This image is a fusion of elements from a random place in World of Warcraft with a random place in Peru. It was inspired by the book World of Warcraft: Chronicle Volume 1 by Chris Metzen and Matt Burns. A must-read for any WoW fan, this book dives deep into the lore of the Warcraft universe.
Prompt: Create a realistic scenery image that blends elements from a random place in World of Warcraft and a random place in Peru, inspired by the book “World of Warcraft: Chronicle Volume 1. by Chris Metzen and Matt Burns” The scene should evoke an ancient, mythological atmosphere, with features like towering statues, ancient ruins, and celestial landscapes reminiscent of Azeroth, combined with the majestic setting of Machu Picchu in Peru. The composition should merge fantasy with reality, creating a grand, epic scene that embodies the rich history and mystical essence of both worlds.
Rise of the Horde in the Andes: A Fusion of World of Warcraft and Peruvian Landscapes
This realistic scenery image blends elements from a random place in World of Warcraft with a random place in Peru. It was inspired by Christie Golden’s book World of Warcraft: Rise of the Horde & Lord of the Clans. This epic book dives into Thrall’s journey to save Azeroth and the Horde.
Prompt: Create a realistic scenery image that blends elements from a random place in World of Warcraft and a random place in Peru, inspired by the book “World of Warcraft: Rise of the Horde & Lord of the Clans.” The scene should evoke a sense of epic battles and ancient power, with elements like orcish fortresses, rugged landscapes, and imposing war banners from Azeroth combined with a real-world Peruvian location like the rugged Andes mountains. The composition should merge fantasy with reality, creating a powerful, dramatic scene that embodies the struggle and history of both worlds.
The Last Guardian’s Legacy: A Fusion of Azeroth’s Magic and Peru’s Ancient Ruins
This realistic scene was brought to life based on the book “Warcraft: The Last Guardian by Jeff Grubb.” The scene blends elements of ancient magic, looming threats, and the clash between light and darkness from Azeroth with the ancient ruins of Choquequirao in Peru. The resulting image creates a powerful atmosphere that captures the mysterious essence of both worlds.
Prompt: Create a realistic scenery image that blends elements from a random place in World of Warcraft and a random place in Peru, inspired by the book “Warcraft: The Last Guardian.” The scene should evoke a sense of ancient magic, looming threats, and the clash between light and darkness. Features like mystical towers, dark forests, and ominous skies from Azeroth should be combined with a real-world Peruvian location, such as the ancient ruins of Choquequirao. The composition should merge fantasy with reality, creating a mysterious and powerful atmosphere that reflects the struggle and history of both worlds.
Illidan’s Vengeance: The Fusion of Outland’s Darkness with Peru’s Ancient Mysteries
For this one, the inspiration came from “Illidan: World of Warcraft” by William King. The scene blends the twisted landscapes of Outland, fel orcs, and eerie green skies of Azeroth with the ancient city of Chan Chan in Peru. The resulting image creates an intense and dramatic atmosphere, reflecting Illidan’s complex character and the struggles he faces.
Prompt: Create a realistic scenery image that blends elements from a random place in World of Warcraft and a random place in Peru, inspired by the book ‘Illidan: World of Warcraft.’ The scene should evoke a sense of dark power, justice, and vengeance, with features like the twisted landscapes of Outland, fel-infused orcs, and eerie green skies from Azeroth combined with a real-world Peruvian location such as the mysterious and ancient city of Chan Chan. The composition should merge fantasy with reality, creating an intense and dramatic atmosphere that reflects the complex character of Illidan and the struggles he faces.
Epic Convergence: The Sundering of Worlds
This one blends elements from the towering forests of Kalimdor in World of Warcraft with the ancient, mystical landscapes of the Sacred Valley in Peru. The image reflects the apocalyptic battle and ancient powers described in “WarCraft: War of The Ancients # 3: The Sundering by Richard A. Knaak.” The fusion of arcane magic and real-world Peruvian landscapes creates a dynamic and intense atmosphere, perfect for depicting the final clash between good and evil.
Prompt: Create a realistic scenery image that blends elements from a random place in World of Warcraft and a random place in Peru, inspired by the book ‘WarCraft: War of The Ancients # 3: The Sundering.’ The scene should evoke a sense of epic struggle, ancient powers, and the clash between good and evil, with features like the towering forests of Kalimdor, arcane magic, and swirling vortexes from Azeroth combined with a real-world Peruvian location such as the Sacred Valley of the Incas. The composition should merge fantasy with reality, creating a dynamic and intense atmosphere that reflects the final, apocalyptic battle in the War of the Ancients.
Echoes of Azeroth in the Heart of Peru: A Fusion of Worlds
This realistic scenery image is a unique blend inspired by the book “Tides of Darkness by Aaron Rosenberg” from the World of Warcraft series. The image captures the essence of ancient mysteries and epic landscapes by merging a random place from Azeroth with the majestic Machu Picchu in Peru. This fusion creates a surreal yet captivating environment that bridges fantasy and reality.
Prompt: Create a realistic scenery image that blends elements from a random place in World of Warcraft and a random place in Peru. Take inspiration from Aaron Rosenberg’s book Tides of Darkness, focusing on the mystical and ancient aspects of both worlds. The image should evoke a sense of wonder and mystery, capturing the essence of both the fantasy world and the real-world location.
Epic Fusion of Worlds: A Mystical Peruvian Landscape Meets the World of Warcraft
This realistic scenery image seamlessly blends the mystical atmosphere of a place in World of Warcraft with the natural beauty of a Peruvian landscape. Taking inspiration from the book “World of Warcraft: Wolfheart by Richard A. Knaak,” the image captures the essence of both worlds, merging them into a single, awe-inspiring scene.
Prompt: Create a realistic scenery image that blends elements from a random place in World of Warcraft and a random place in Peru. The image should take inspiration from the book “World of Warcraft: Wolfheart by Richard A. Knaak.” The scene should capture the mystical and epic atmosphere typical of World of Warcraft, combined with the rugged, natural beauty of a Peruvian landscape.
The Enchanted Depths of the Amazon
This image blends elements of World of Warcraft’s enchanted forests and the Amazon Rainforest, drawing inspiration from Richard A. Knaak’s “World of Warcraft: Stormrage.” The scene features dense jungle vegetation, glowing plants, a winding river, and hidden ruins that combine Night Elf and ancient Amazonian architectural styles. The vibrant yet mysterious atmosphere suggests an ancient, magical power within this untouched wilderness.
Prompt: Create a realistic widescreen scenery image that combines the enchanted forests of World of Warcraft, inspired by ‘Stormrage’ by Richard A. Knaak, with the ancient, mystical landscape of the Amazon Rainforest in Peru. The image should feature dense, towering trees with glowing, ethereal plants and a river winding through the lush jungle. Hidden within the forest, there should be ruins that merge Night Elf and ancient Amazonian architectural elements, partially overtaken by the vibrant, magical flora. The atmosphere should be vibrant and mysterious, with beams of light breaking through the canopy and illuminating the scene. The color palette should include deep greens, rich browns, and soft glowing blues and purples, evoking a sense of magical realism and ancient power.
Mystical Mountain Monastery
This image blends the rugged landscapes of Pandaria from World of Warcraft with the remote mountain regions of the Peruvian Andes. Inspired by Michael A. Stackpole’s “Vol’jin: Shadows of the Horde,” it features steep cliffs with terraced fields, a dense jungle, and a hidden monastery. The scene includes ancient stone structures that merge Pandaren and Incan designs with a calm yet tense atmosphere.
Prompt: Create a realistic widescreen scenery image that blends the rugged landscapes of Pandaria from World of Warcraft, inspired by ‘Vol’jin: Shadows of the Horde’ by Michael A. Stackpole, with the remote mountain regions of the Peruvian Andes. The image should feature steep cliffs with terraced fields, dense jungle, and a hidden monastery. Include elements like ancient stone structures that combine Pandaren and Incan designs. The atmosphere should feel calm yet tense, with soft light filtering through the misty air. The color palette should include earthy tones of green and brown, with touches of gold and gray.
Join us on this incredible generative AI journey and be a part of the revolution. Stay tuned for updates and insights on generative AI by following us on X or LinkedIn.
TL;DR: Tradespace exploration is a method for making decisions based on data. It involves considering different options and their potential outcomes in order to determine the best course of action. This approach can help organizations make more informed and effective decisions.
Disclaimer: This post has been created automatically using generative AI. Including DALL-E, Gemini, OpenAI and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us
Introduction
In today’s fast-paced and competitive business world, making informed decisions is crucial for success. With the rise of technology and the abundance of data, organizations have access to a vast amount of information that can help them make better decisions. However, simply being data-informed is no longer enough. To stay ahead of the game, businesses must become data-driven. One powerful tool that can aid in this transformation is tradespace exploration.
What is Tradespace Exploration?
Tradespace exploration is a method used to analyze and evaluate trade-offs between different options or alternatives. It allows decision-makers to consider multiple factors and variables simultaneously to find the optimal solution. This approach is commonly used in engineering and product design, but it can also be applied to other industries such as marketing, finance, and operations.
Moving from Data-Informed to Data-Driven Decisions
While being data-informed means using data to support and guide decision-making, being data-driven takes it a step further. It means using data as the primary driver of decisions. In other words, data becomes the foundation upon which all decisions are made. This shift is crucial in today’s fast-paced and competitive business environment, where decisions must be made quickly and accurately.
The Role of Data in Tradespace Exploration
Data plays a crucial role in tradespace exploration. It provides the necessary information to identify and evaluate different trade-offs and options. With the help of data, decision-makers can assess the impact of each option on various factors such as cost, time, resources, and customer satisfaction. This allows them to make more informed and strategic decisions that align with their goals and objectives.
Benefits of Tradespace Exploration
Tradespace exploration offers numerous benefits to organizations. Firstly, it allows decision-makers to consider a wide range of options and factors, leading to more robust and well-informed decisions. It also helps in identifying potential risks and opportunities, enabling businesses to mitigate risks and capitalize on opportunities. Additionally, tradespace exploration promotes collaboration and communication among team members, leading to a more efficient decision-making process.
Conclusion
In conclusion, tradespace exploration is a powerful tool that can help businesses move from being data-informed to data-driven. By utilizing this method, organizations can make more strategic and well-informed decisions that align with their goals and objectives. With the abundance of data available, it is essential for businesses to embrace tradespace exploration and harness the power of data to stay ahead of the competition. By incorporating data into decision-making, organizations can make more informed and successful choices, leading to improved efficiency and effectiveness. Data-driven decisions are becoming increasingly essential in all industries, and it is crucial for individuals and organizations to understand and embrace this approach to stay competitive in a constantly evolving landscape.
Join us on this incredible generative AI journey and be a part of the revolution. Stay tuned for updates and insights on generative AI by following us on X or LinkedIn.
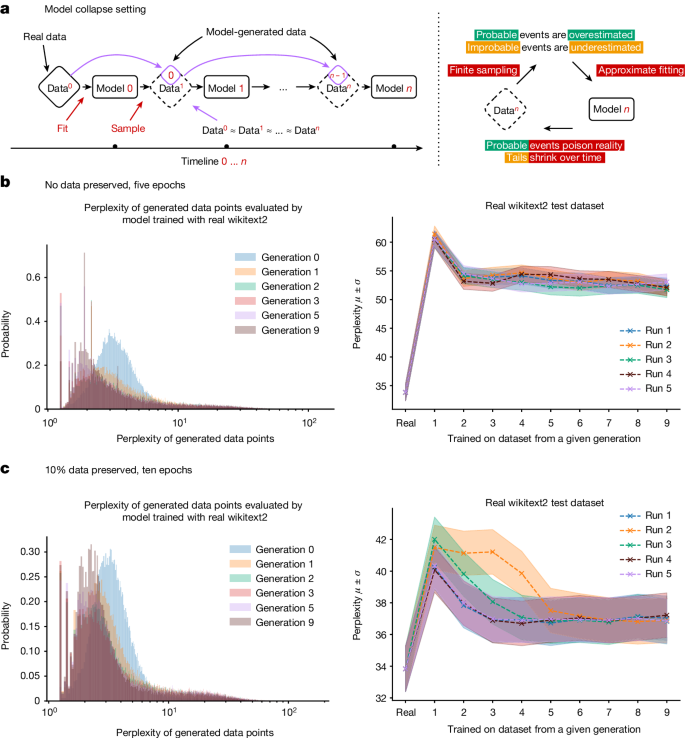
TL;DR: Model collapse is a phenomenon where AI models trained on recursively generated data gradually lose their ability to produce accurate and diverse outputs [1] [2]. This occurs due to over-representation of common patterns and forgetting less-common elements. This results in a progressive loss of information and a decrease in the model’s ability to generate high-quality outputs. The phenomenon has been observed in various generative models, including large language models (LLMs) like GPT-3 and GPT-4, as well as in variational autoencoders (VAEs) and other generative models [1] [3]. To prevent model collapse, researchers suggest strategies like mixing real and synthetic data, using adaptive regularization, and accumulating data over time [4] [5]. While this remains a significant challenge, ongoing research aims to mitigate its effects [6].
Disclaimer: This post has been created with the help of generative AI. Including DALL-E, Gemini, OpenAI and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us
Model collapse occurs when AI models, over successive generations, begin to forget rare events, leading to increasingly inaccurate outputs. As models are trained on data produced by previous iterations, they start to distort reality, introducing errors that compound over time, as shown in the progressive increase in perplexity in later generations [1].What Is Model Collapse?
Model collapse refers to the phenomenon where AI models, when trained on data generated by other AI models (including their own previous outputs), begin to lose the diversity and depth of the original data distribution [1]. Over time, these models increasingly produce outputs that are repetitive, less accurate, and less reflective of the true distribution of human-generated data [2]. This process can ultimately lead to a scenario where the model’s outputs become degenerate, losing the ability to generate useful and meaningful content.
The concern of model collapse is particularly relevant as AI-generated content becomes more prevalent online. With more AI-generated data being used to train new models, the risk of recursively generated data leading to model collapse increases.
Causes of Model Collapse
The underlying causes of model collapse are multifaceted, involving several types of errors that accumulate over successive generations of training:
Statistical Approximation Error: This error occurs due to the finite number of samples used in training. As models are trained on recursively generated data, rare events in the original data distribution may not be sampled frequently enough, leading to their gradual disappearance [1].
Functional Expressivity Error: This error is related to the limitations in the model’s ability to approximate the true data distribution. As neural networks are not perfect approximators, they may introduce errors that compound over successive generations, leading to a divergence from the original distribution [1].
Functional Approximation Error: This error arises from limitations in the learning procedures themselves, such as the choice of optimization algorithms or loss functions. These limitations can cause the model to overfit certain aspects of the data while ignoring others, leading to a progressively narrower understanding of the data [1].
Each of these errors contributes to the overall degradation of the model’s performance, ultimately leading to model collapse.
The Impact of Model Collapse on Different Generative Models
Model collapse is a universal issue that affects various types of generative models. Here’s how it manifests in some of the most common models:
Generative Adversarial Networks (GANs): In GANs, model collapse can result in the generator producing a limited variety of outputs, often converging on a few specific examples, leading to a loss of diversity in the generated content.
Variational Autoencoders (VAEs): In VAEs, model collapse may lead to the generated samples becoming less representative of the original data distribution, particularly in the tails, where the diversity of the content is crucial.
Large Language Models (LLMs): LLMs like GPT-3 and GPT-4 are especially vulnerable to model collapse when trained on recursively generated data. As these models are fine-tuned on outputs generated by previous versions, they risk losing the richness and variety inherent in human language, resulting in repetitive and less coherent text generation.
Theoretical Insights: Why Model Collapse Happens
To understand why model collapse happens, it’s essential to delve into the theoretical foundations. One useful framework is the concept of Markov chains, which can model the progression of data through successive generations of training. In this model, each generation of data is dependent on the previous one. If certain rare events in the data are not sampled adequately, they will eventually disappear, leading to a narrowing of the model’s output.
Another theoretical approach involves analyzing the behavior of Gaussian models. It has been shown that when models are trained recursively on their own outputs, they tend to collapse to a distribution with zero variance over time. This means that the model’s outputs become increasingly repetitive and less diverse, losing the ability to generalize from the original data.
Identifying Early Signs of Model Collapse
Model collapse can go unnoticed as initial performance appears to improve while the model subtly loses accuracy on minority data. This issue arises from model-induced distribution shifts (MIDS) that embed biases into data, leading to fairness feedback loops and exacerbating inequalities over time [7].
Hidden Performance Decline: Models may show apparent gains in overall metrics while losing accuracy, especially on minority data.
Fairness Feedback Loops: MIDS can lead to fairness feedback loops, exacerbating biases in the model, even in datasets that initially appear unbiased. This problem can particularly harm the representation of minoritized groups, reinforcing existing disparities.
Algorithmic Reparation as a Solution: The concept of algorithmic reparation (AR) is introduced as a proactive approach to address these fairness issues. AR involves curating representative training data to correct biases and improve the model’s fairness over time. This section highlights the importance of recognizing and mitigating these unfairness feedback loops in machine learning systems.
Practical Examples: Model Collapse in Action
The effects of model collapse can be seen in practical scenarios, particularly in the case of large language models. For example, a study involving the fine-tuning of a language model on data generated by a previous version of the same model revealed a gradual decline in the model’s performance. Initially, the model performed well, but as it was trained on recursively generated data over multiple generations, the quality of its outputs deteriorated. The generated text became more repetitive, less accurate, and increasingly disconnected from the original training data.
This degradation was quantified using a metric known as perplexity, which measures how well a model predicts the next word in a sequence. As model collapse set in, the perplexity increased, indicating a decline in the model’s ability to generate coherent and contextually appropriate text.
The Broader Implications of Model Collapse
The implications of model collapse extend beyond individual models to the broader AI ecosystem. As more AI-generated content populates the internet, the risk of recursively generated data becoming a significant portion of training datasets increases. This could lead to a situation where AI models trained on this data produce outputs that are increasingly disconnected from the real world, reducing their utility and reliability.
Moreover, model collapse raises important questions about data provenance. As it becomes harder to distinguish between human-generated and AI-generated content, ensuring that future AI models are trained on high-quality, diverse data becomes more challenging. This underscores the need for robust mechanisms to track the provenance of training data and to filter out low-quality or AI-generated content.
Mitigating the Risks of Model Collapse
To mitigate the risks associated with model collapse, several strategies can be employed:
Human-in-the-Loop Training: Involving humans in the training process can help ensure that models are exposed to a diverse range of data and do not become overly reliant on AI-generated content. This can include using human evaluators to filter and curate the training data.
Data Provenance and Filtering: Developing methods to track the origin of training data can help distinguish between human-generated and AI-generated content. This may involve using metadata or other markers to identify the source of the data.
Robust Evaluation Metrics: Implementing more comprehensive evaluation metrics that go beyond simple accuracy measures can help detect early signs of model collapse. For example, metrics that assess the diversity and richness of the model’s outputs can provide valuable insights into its performance.
Continual Learning with Real-World Data: To prevent models from collapsing, it is crucial to continue training them on real-world data that accurately reflects the full distribution of human language and experience. This may involve supplementing web-scraped data with carefully curated datasets that are less likely to contain AI-generated content.
The Future of Generative AI and the Challenges of Model Collapse
As AI technology continues to advance, the challenge of model collapse will become increasingly important. Ensuring that AI models remain robust and capable of generating high-quality content requires a careful balance between innovation and the preservation of data integrity. By understanding the causes and implications of model collapse, and by implementing strategies to mitigate its risks, we can continue to harness the power of generative AI while safeguarding its future potential.
In conclusion, model collapse is a significant issue that must be addressed to ensure the continued success and reliability of generative AI. As the use of AI-generated content grows, so too does the importance of maintaining the integrity of the data used to train these models. By taking proactive steps to mitigate the risks of recursively generated data, we can ensure the long-term sustainability and reliability of AI systems.
References
[1] Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., & Gal, Y. (2024). AI models collapse when trained on recursively generated data. Nature, 631(8022), 755-759. https://doi.org/10.1038/s41586-024-07566-y
[2] Shumailov, I., Shumaylov, Z., Zhao, Y., Gal, Y., Papernot, N., & Anderson, R. (2023). The Curse of Recursion: Training on Generated Data Makes Models Forget. ArXiv. /abs/2305.17493
[3] Wenger, E. (2024). AI produces gibberish when trained on too much AI-generated data. Nature, 631(8022), 742-743. https://doi.org/10.1038/d41586-024-02355-z
[4] Gerstgrasser, M., Schaeffer, R., Dey, A., Rafailov, R., Sleight, H., Hughes, J., Korbak, T., Agrawal, R., Pai, D., Gromov, A., Roberts, D. A., Yang, D., Donoho, D. L., & Koyejo, S. (2024). Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data. ArXiv. /abs/2404.01413
[5] Seddik, M. E., Chen, S., Hayou, S., Youssef, P., & Debbah, M. (2024). How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse. ArXiv. /abs/2404.05090
[6] Coldewey, D. ‘Model collapse’: Scientists warn against letting AI eat its own tail. TechCrunch. https://techcrunch.com/2024/07/24/model-collapse-scientists-warn-against-letting-ai-eat-its-own-tail/
[7] Wyllie, S., Shumailov, I., & Papernot, N. (2024). Fairness Feedback Loops: Training on Synthetic Data Amplifies Bias. ArXiv. /abs/2403.07857
“New to time series analysis? Check out these 9 essential prompts for using ChatGPT to analyze trends and make forecasts. This detailed guide covers advanced techniques in an easy-to-understand way.”
Disclaimer: This post has been created automatically using generative AI. Including DALL-E, Gemini, OpenAI and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us
Introduction to Time Series Analysis
Time series analysis is a powerful tool used in various fields such as finance, economics, and marketing to analyze and forecast trends over time. With the advancement of technology, there are now various tools available to perform time series analysis, one of which is ChatGPT. ChatGPT is an advanced AI-based platform that can assist in time series analysis by generating accurate predictions and insights. In this blog post, we will discuss nine essential prompts for time series analysis with ChatGPT, which can help you in performing meticulous and advanced techniques for trend analysis and forecasting.
1. Understanding the Data
The first step in any time series analysis is to understand the data. This involves identifying the time series patterns, trends, and seasonality. ChatGPT can assist in this process by analyzing the data and providing insights on the patterns and trends present in the data. It can also identify any outliers or anomalies that may affect the analysis.
2. Identifying the Appropriate Model
Choosing the right model is crucial for accurate time series analysis. ChatGPT can help in identifying the appropriate model for your data, whether it is a simple moving average, exponential smoothing, or ARIMA. It takes into account the characteristics of your data and suggests the best model for forecasting.
3. Trend Analysis
Trend analysis is an essential aspect of time series analysis as it helps in understanding the direction and magnitude of the trend. ChatGPT can assist in identifying the trend in your data and providing insights on whether it is increasing, decreasing, or remaining constant. It can also predict the future trend and its potential impact on the data.
4. Seasonal Analysis
Seasonality is a common pattern in time series data, where the data exhibits a regular pattern over a specific period. ChatGPT can detect seasonality in your data and provide insights on the seasonal patterns and their impact on the data. It can also help in predicting future seasonal patterns and their potential impact on the data.
5. Forecasting
Forecasting is the process of predicting future values of a time series. ChatGPT can assist in forecasting by analyzing historical data and identifying patterns and trends. It can then use this information to generate accurate predictions for future values, taking into account any seasonal or trend effects.
6. Interpreting Results
Interpreting the results of time series analysis can be challenging, especially for those without a background in statistics. ChatGPT can help in interpreting the results by providing easy-to-understand insights and visualizations.
In conclusion, these 9 essential prompts for time series analysis with ChatGPT provide a comprehensive and detailed guide for advanced techniques in trend analysis and forecasting. Through a meticulous approach, users can gain a deeper understanding of time series data and make more accurate predictions for future trends. By following these prompts, individuals can unlock the full potential of ChatGPT for their time series analysis needs.
Join us on this incredible generative AI journey and be a part of the revolution. Stay tuned for updates and insights on generative AI by following us on X or LinkedIn.
TL;DR: Data science can help businesses use insights to drive customer value. By analyzing data, companies can make better decisions and improve customer experience. It’s all about using data to make a positive impact on customers and their satisfaction.
Disclaimer: This post has been created automatically using generative AI. Including DALL-E, Gemini, OpenAI and others. Please take its contents with a grain of salt. For feedback on how we can improve, please email us
Introduction: The Importance of Data Science in Maximizing Customer Value
In today’s digital age, data is king. Companies are constantly collecting and analyzing vast amounts of data to gain insights into their customers’ behaviors and preferences. This has led to the rise of data science, a field that combines statistics, computer science, and business to extract meaningful insights from data. By leveraging data science, companies can better understand their customers and tailor their strategies to maximize customer value. In this blog post, we will explore how data science can be used to drive impactful changes that can ultimately lead to increased customer value.
Understanding Customer Behaviors and Preferences through Data Science
One of the key ways data science can maximize customer value is by providing a deeper understanding of customer behaviors and preferences. By analyzing data from various sources, such as customer interactions, purchase history, and social media, data scientists can identify patterns and trends that can help businesses understand what their customers want and need. This can inform product development, marketing strategies, and customer service, ultimately leading to a more personalized and satisfying customer experience.
Predictive Analytics: Anticipating Customer Needs and Proactively Meeting Them
Data science also enables companies to use predictive analytics to anticipate customers’ future needs and proactively meet them. By analyzing past data, data scientists can build models that predict future behaviors and preferences. This can help companies tailor their offerings to align with what their customers are likely to want in the future, leading to increased customer satisfaction and loyalty. For example, a retail company can use predictive analytics to forecast which products will be in high demand during certain seasons and stock up accordingly.
Personalization: Tailoring Strategies to Individual Customers
Another way data science can maximize customer value is through personalization. By analyzing data on individual customers, companies can tailor their strategies to each customer’s specific needs and preferences. This can range from personalized product recommendations to targeted marketing campaigns. By making customers feel understood and valued, personalization can greatly enhance the customer experience and increase customer loyalty.
Optimizing Business Operations and Processes with Data Science
Data science is not just limited to customer-facing strategies. It can also be used to optimize business operations and processes, leading to increased efficiency and cost savings. By analyzing data on supply chain management, inventory levels, and production processes, companies can identify areas for improvement and make data-driven decisions to streamline their operations. This can ultimately lead to a better customer experience, as well as increased profitability.
Conclusion
In today’s rapidly evolving business landscape, data science has become a crucial tool for companies to understand their customers and drive growth. By utilizing insights from data, businesses can effectively maximize customer value and ultimately achieve greater success. With the advancements in technology and the vast amount of data available, it is clear that data science will continue to play a vital role in shaping the future of businesses. By leveraging this powerful tool, companies can stay ahead of the competition and deliver exceptional value to their customers, leading to sustainable business success.
Join us on this incredible generative AI journey and be a part of the revolution. Stay tuned for updates and insights on generative AI by following us on X or LinkedIn.











: A Comprehensive Paper Walkthrough")
: A Comprehensive Paper Walkthrough")